简介:SMC-R 是如何加速 TCP 应用?
编者按:TCP 协议作为当前使用最为广泛的网络协议,场景遍布移动通信、数据中心等。对于数据中心场景,通过弹性 RDMA 实现高性能网络协议 SMC-R,透明替换应用 TCP 协议,实现应用网络透明加速。本文整理自龙蜥大讲堂第 15 期,视频精彩回放已上传至龙蜥官网,欢迎查看!

为什么需要新的内核网络协议栈?
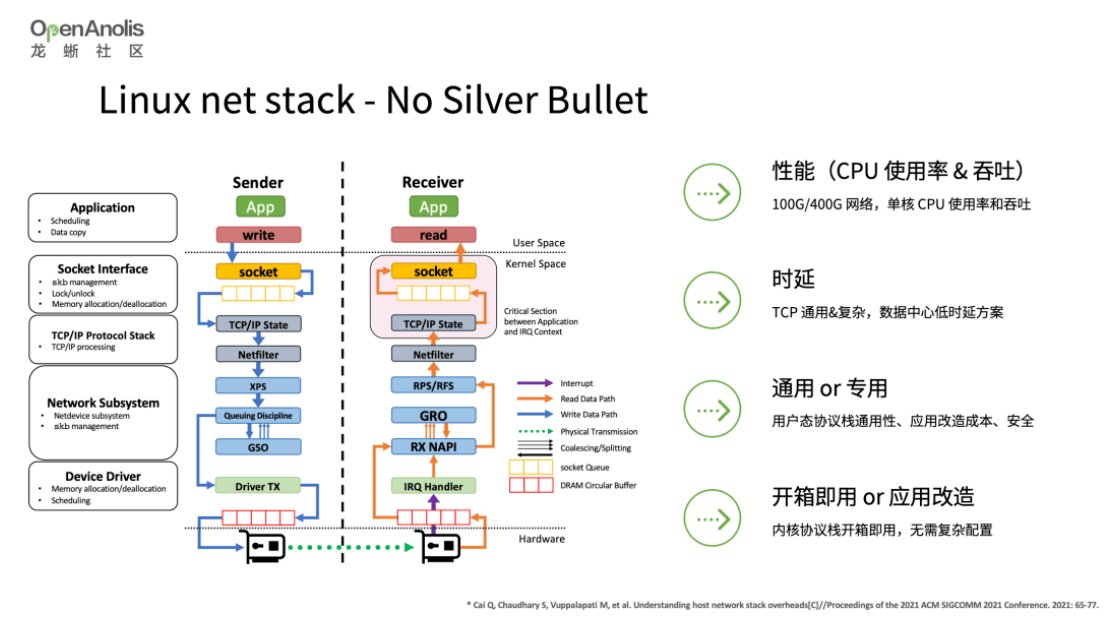
Linux 内核网络协议栈没有银弹,当前 Linux 网络协议栈是在性能(吞吐、CPU 使用率)、时延和通用性权衡下的实现。在真实场景中,我们可能需要高性能但是并不通用的用户态协议栈,亦或是通用、更高性能更低时延的方案,但是基于传统以太网卡的方案很难有大幅度的提升,更多是基于硬件的红利,例如 100G/400G 网络。鉴于此,我们考虑是否可以基于其他高性能网络,提供 TCP 兼容的行为和 socket 接口,提供更优的性能。
基于共享内存的网络通信
在谈跨主机通信之前,我们先把视线放到单机维度,如何在单机维度实现 IPC?下面是几种常见的 IPC 方式:
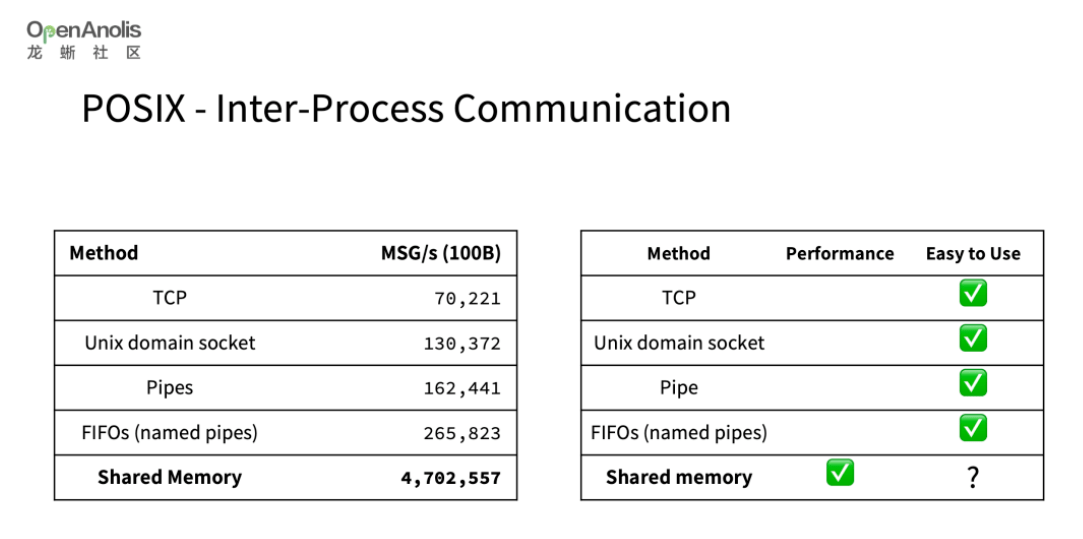
不出意外,共享内存是最快的 IPC 方式,但是缺少一种 OS 层面的统一实现和接口,多数是在语言的 library 中提供。
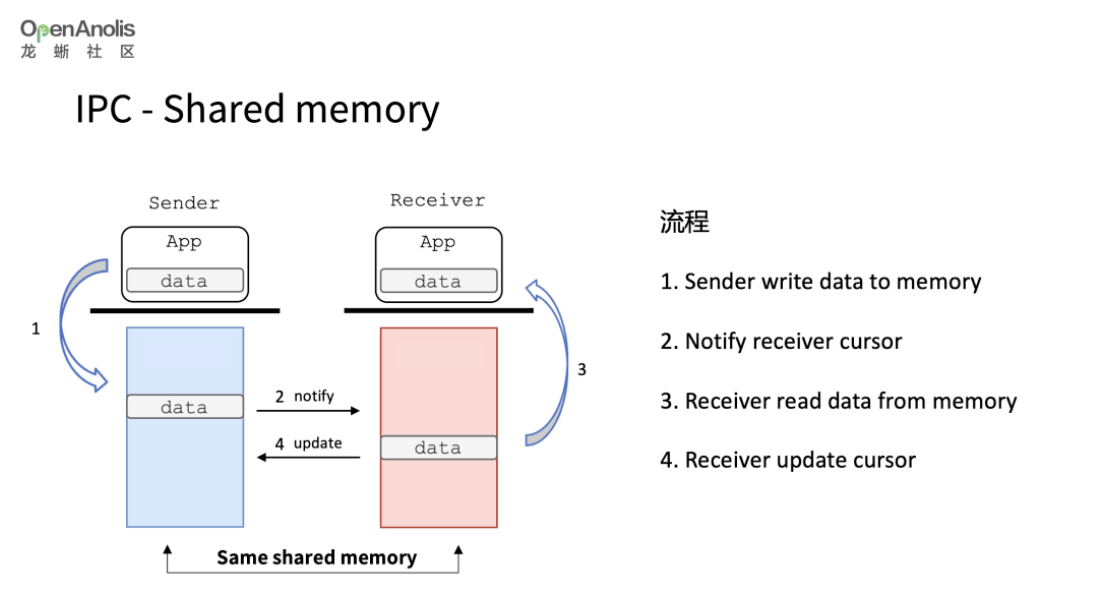
这里我们分解一下单机维度的共享内存 IPC 流程:
如果有一种技术,可以实现在两台机器间“搬运”内存,那么我们可以把这种高性能 IPC 方案从单机维度拓展到不同的主机间。很显然,Remote Direct Memory Access RDMA 可以帮助我们高效地搬运内存。
相对于单机的共享内存通信流程,基于 RDMA 的流程:
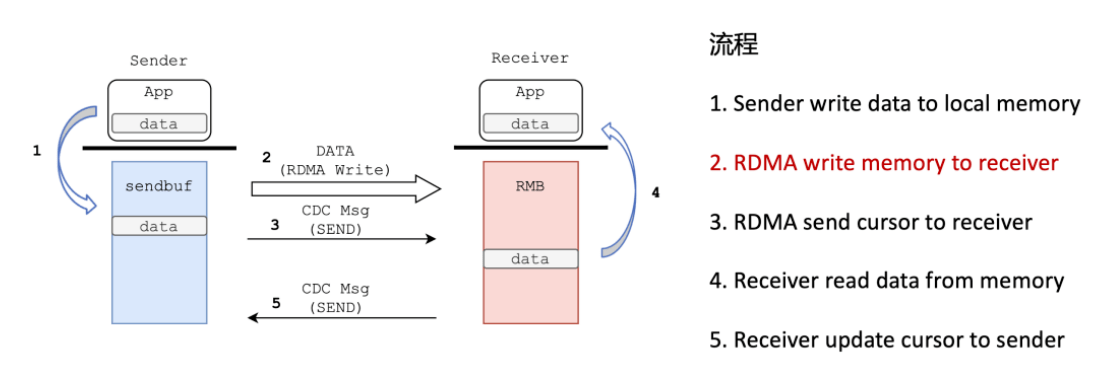
基于 RDMA 的共享内存模型,SMC-R 应运而生,SMC-R 缩写即为 Shared Memory Communcation over RDMA。
下面让我们看下 SMC-R 是如何加速 TCP 应用。
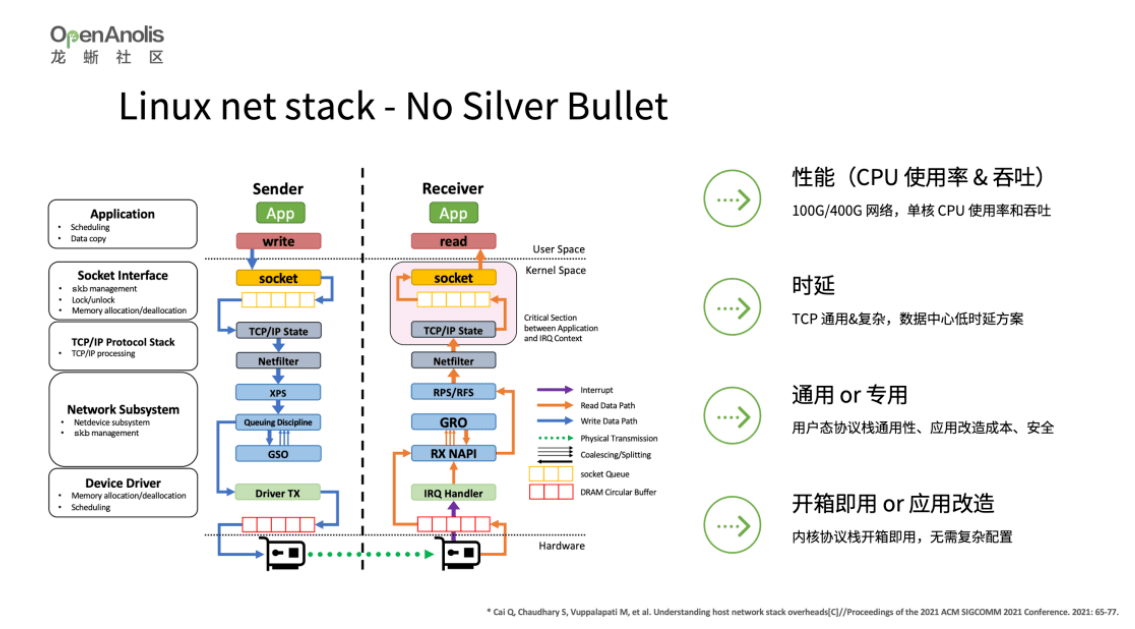
SMC-R 是一种混合协议,即通过 TCP 实现建联时信息交互,通过 RDMA 网络实现数据路径高性能数据传输。同时,一旦 RDMA 链路建联失败,可以 fallback 到 TCP,实现兜底 TCP 的能力。除此之外,SMC-R 借助多个 RNIC,可以实现运行时的故障迁移,确保运行时可靠性。
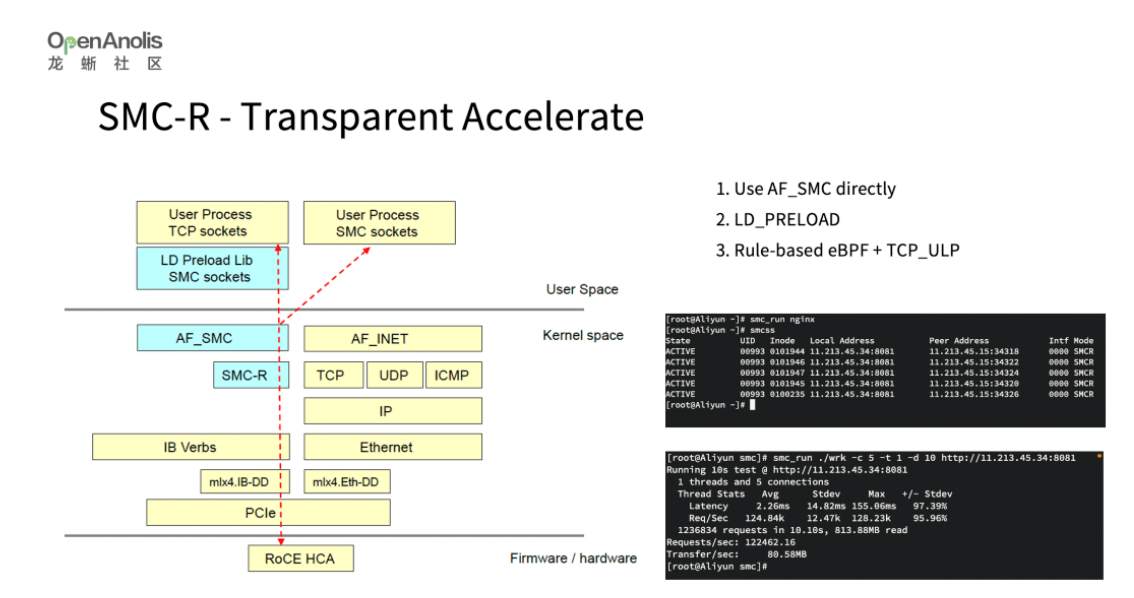
RDMA 本身提供了 verbs 接口供应用使用,SMC-R 基于共享内存的模型,提供了一套完全兼容 TCP socket 的内核接口,可以通过 LD_PRELOAD 基于 eBPF 的规则替换等方式,实现将 TCP socket 透明替换成 SMC socket,进而实现透明替换和加速。
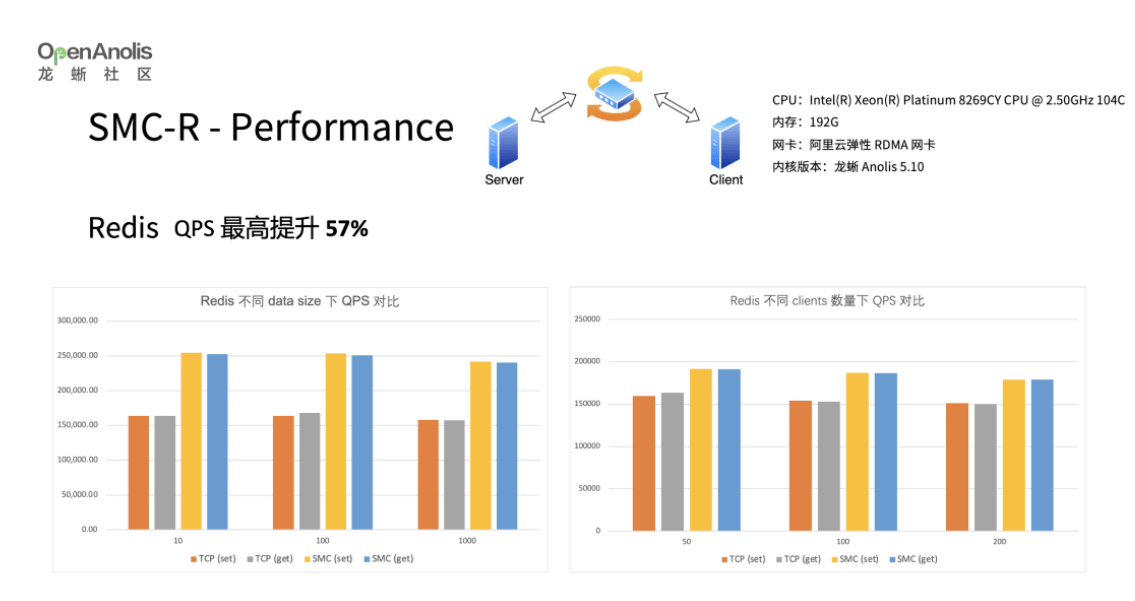
基于 SMC-R 透明替换,我们测试了几种应用场景,其中 Redis 有最高 57% 的性能提升,此时 Redis 无需进行任何改造,即可享受 SMC-R 带来的性能加速。
使用 SMC-R 加速应用
透明替换并加速 TCP 应用,可以使用下面三种方案:


SMC-R 在龙蜥
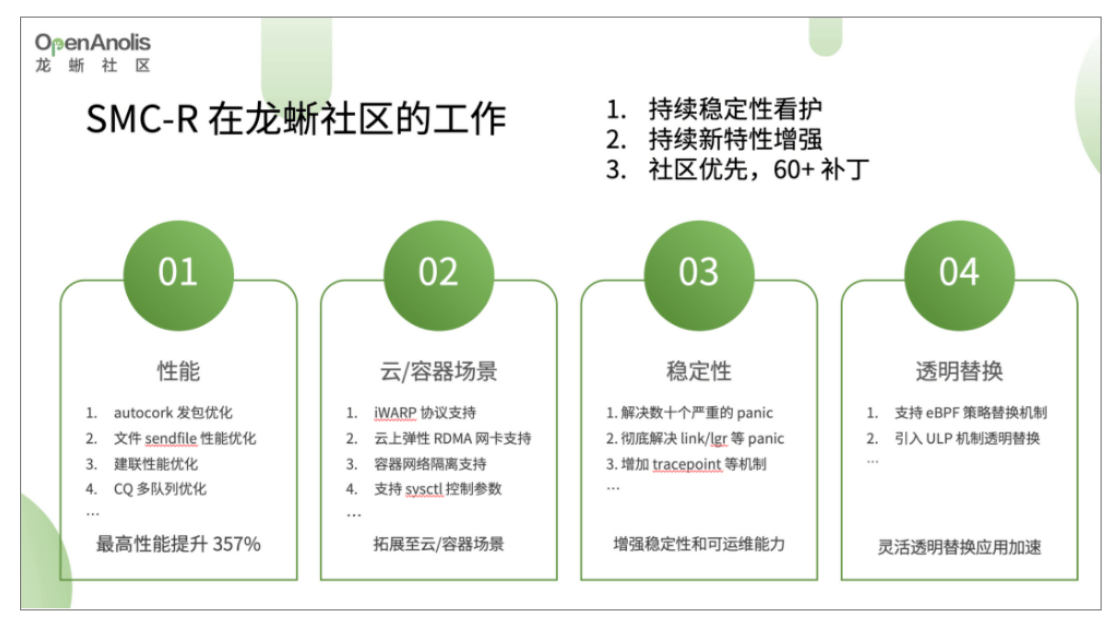
在龙蜥社区中,我们也正在持续不断地增强优化 SMC,包括性能、使用场景、稳定性和透明替换。参与龙蜥社区贡献的半年时间内,共为 Linux 上游社区贡献了 60+ 的补丁。
本次分享只是抛砖引玉,后期更多精彩技术分享还请持续关注龙蜥公众号不迷路。欢迎大家在龙蜥社区交流和分享,相关资料可以从下面的链接中获取。
相关链接地址:
1、代码仓库:hpn-cloud-kernel
2、高性能网络 SIG 地址:High Performance Network – OpenAnolis 龙蜥操作系统开源社区
原文链接:http://click.aliyun.com/m/1000343447/
本文为阿里云原创内容,未经允许不得转载。