
导读
7月6日,后摩智能联合智东西公开课策划推出的「存算一体大算力AI芯片在线研讨会」顺利完结。东南大学电子科学与工程学院副研究员司鑫、后摩智能联合创始人&芯片研发副总裁陈亮、后摩智能联合创始人&产品推出副总裁信晓旭三位主讲人参与了本次在线研讨会并进行了主题分享。
陈亮博士的演讲主题为《从硬件架构到软件工具链,存算一体大算力AI芯片的创新与实践》。他首先以FSD 和Tenstorrent 两个典型的AI处理器架构为例,介绍了传统处理器架构的不足,之后围绕存算单元Macro、层次化的AI核设计、软件工具链、软件栈、编程模型等方面对后摩智能存算一体大算力AI芯片进行了深入讲解。错过直播的朋友,可以点击“阅读原文”观看回放。
本文为陈亮博士的主讲回顾:
大家好,我是后摩智能联合创始人&芯片研发副总裁陈亮,很高兴跟大家做今天的分享,我讲解的主题是《从硬件架构到软件工具链,存算一体大算力AI芯片的创新与实践》,主要从以下三个部分展开介绍:
第一部分会讲下典型的AI处理器架构,这里会围绕特斯拉FSD 和Tenstorrent 芯片做介绍;
第二部分是后摩AI处理器的架构设计,主要分为存算单元Macro 的设计考虑、层次化的AI 核的设计,还有基于存算一体的AI核设计过程中的一些工程化考虑;
第三部分是软件工具链方面,我们知道每个NPU,每个AI核都有自己的软件工具链、编译器等,我会介绍下后摩智能AI处理器的软件栈和编程模型。
一、典型的AI处理器架构
第一个典型的AI处理器架构是特斯拉的FSD。特斯拉FSD 发布于2017年左右,是一个非常简洁、高效的设计,因为它是特斯拉专用的AI处理器,主要的组成部分包括一个96×96的MACs 阵列、一个片内32MB的SRAM、一个非常简洁的指令集,指令集里面包括了两个DMA 指令、三个点乘指令、一个scale 即标量指令、一个eltwise 指令和一个stop 指令。如果不算stop 指令,FSD 只有7条计算指令。
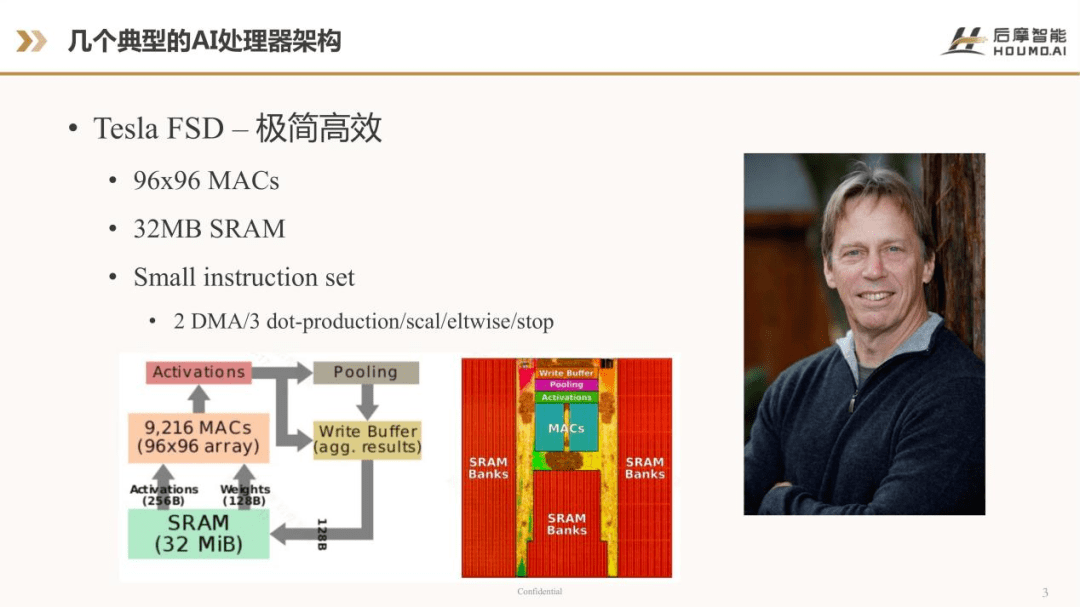
上图的下半部分是它的架构图和版图,从它的架构图和版图来看,它具有非常简洁的设计,带来的好处是非常高效。当时在计算效率、能效比等方面,FSD 要比英伟达的GPU 高几个量级。这也是因为应用的场景不一样,它是一个专用的AI处理器,特斯拉自己的算法运行在特定的处理器上。FSD 架构的主要设计者是吉姆·凯勒,他是处理器领域架构设计的大牛,简洁设计也跟他个人的风格有关,他本人是一个非常崇尚极简主义的架构师。
第二个典型的AI处理器架构是吉姆·凯勒的另外一个作品,这是他近两年加盟的一个新创业公司Tenstorrent,Warmhole 是2021年他们公司一款芯片的名字。我们认为Tenstorrent Warmhole,还有常听说过的GraphCore,它们都属于近存计算的范畴。
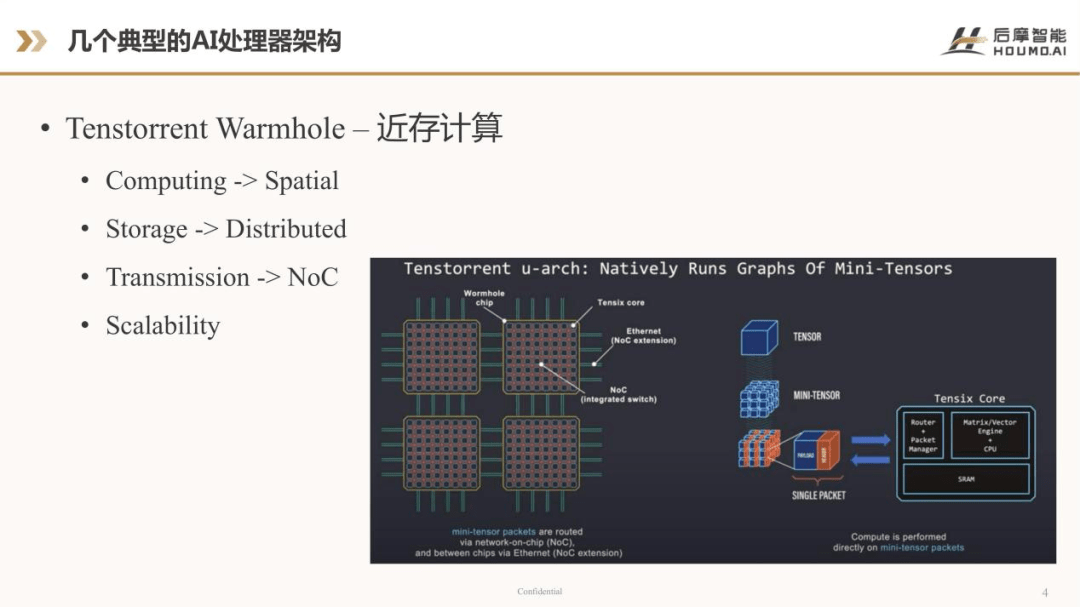
从这两个典型的AI处理器架构可以看出,经过一段时间的演变,传统存储和计算分离的架构已经演进成了近存计算。那近存计算是指什么呢?从上图可以看出整个芯片架构的概况。左下角大的方块,是它的芯片,芯片内部由若干个Tensix core 组成,这些小方块就是Tensix core,这些Tensix core 之间是用Network-on-chip,即NoC 连接在一起的。若干个二维的Tensix core 阵列通过NoC 连接在一起,组成一个芯片,芯片间又通过Ethernet 把芯片连接在一起,这样在芯片间再做一个2Dmesh 扩展。
从计算的角度来看,若干个Tensix core 可以同时完成一个大的Tensor 计算,一个Tensor 可以分解成若干个mini-Tensor,每个mini-Tensor 可以分布在不同的Tensix core 上运行。Tensix core 看起来也是相对简洁的设计,包括了一个CPU matrix vector Engine,再加上近存部分,就是它的SRAM,每一个Tensix core 里有一小块SRAM。除此之外,为了增强数据共享,还增加了Router 和Packet Manager 的处理单元,来保证数据在不同的小Tensix core 之间,还有芯片之间做数据的传输和互联。
从整个架构来看,可以看到它的计算是一个分布式的计算,它的存储也是一个分布式的存储。每个Tensix core 里边的SRAM 组成了片内相当大的分布式存储资源。有了计算,有了存储,另外一个关键的问题就是数据传输,它使用了Network-on-chip(NoC)的数据传输解决方案。
从设计角的度来看,也是一个非常简洁的设计,基本上可以认为把一个Tensix core 和NoC 设计好之后,不断的执行copy-paste 就可以组成一个大的芯片。因此,它有极好的可扩展性。Warmhole 是Tenstorrent 公司2021年的产品,前几年的产品还非常小,只是一个4×4的Tensix core阵列,现在已经发展成一个非常大的阵列。
从2017年到2021年,可以看到AI处理器的架构已经从传统计算和存储分离的架构,演变成了一个近存的架构。之前司鑫老师也讲过,后摩智能所做的是更进一步把存储和计算完全融合在一起,而不只是一个近存计算。
二、后摩智能AI处理器架构
下面更详细介绍下后摩的AI处理器设计。从Macro 到Cluster,我们认为这是一种分布式计算和集中式计算的折衷,是一种trade off。如上图所示,最右边这是一个Macro,就是刚才司鑫老师讲的一个存算单元,由若干个Macro 组成一个Macro Group array。Macro Group array 在Tile 里面是Tensor Engine 最重要的一个计算单元,Tile 同时又是AI Core 里一个重要的组成部分。Tile 内部除了Tensor Engine 以外,还包括了CPU、Special Function Unit(SFU)、Vector Processor(VP)、还有Shared Memory&Controller。Tile 有点类似于上面讲到的特斯拉FSD Core,包括了非常大的算力,每个Macro Group 可以提供4TOPS 算力,所以它类似一个大算力的Core。
若干个Tile 又可以组成一个AI Core。AI Core 里边除了Tile 之外,还包括了像神经网络处理或者AI计算里的前处理或后处理的处理单元、LDST 单元,还有一个Bus Node 单元,Bus Node 用来在Tile 之间或者Core 之间做数据共享和数据路由的控制来源。
在SOC层面,若干个AI Core 又可以组成一个AI Core Clueter,通过总线将若干个AI Core 连接在一起。所以这是一个层次化的设计,若干个Macro 可以组成一个Macro Group,Macro Group 又组成了一个Tile,若干个Tile 可以组成一个AI Core,若干个AI Core 可以组成一个AI Core Clueter,那我们的算力就可以从最小的1个Macro Group,4TOPS 算力不断叠加,最终可以在1个SoC 里面实现几百TOPS 算力。
接下来我会以这4个层次为基础,详细介绍后摩智能的存算一体大算力AI芯片设计。首先是Macro 存算单元,刚刚司鑫老师也有讲到,存算是有不同的路线可以选择的,包括了一些非易失存储的工艺,还有SRAM 工艺,我们采用的方案是SRAM 工艺。SRAM 方案也有模拟和数字两种实现方式,我们把数字存算称为CIMD,模拟存算称为CIMA。
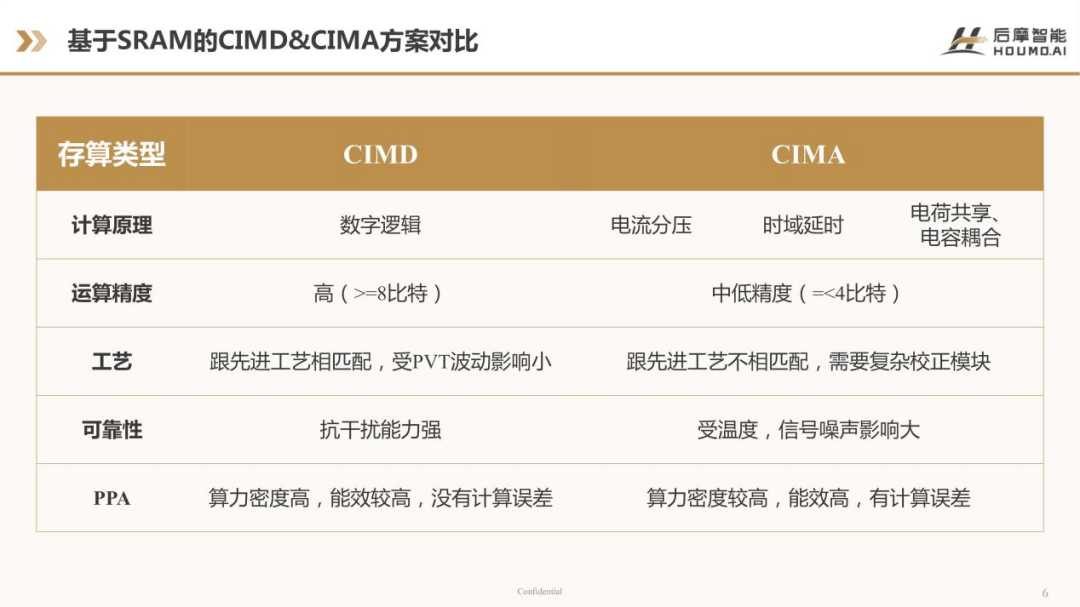
上图的表格中对比了数字和模拟CIM 实现的一些特点。从计算原理上来看,CIMD 是数字逻辑,CIMA 采用了诸如电流分压、时域延时,或者是电荷共享、电容耦合的计算方式;在运算精度方面,CIMD 可以达到8比特甚至更高的比特,比如16比特,但CIMA 的精度会低一些,因为它受限于ADC 的精度,还有它需要把模拟信号转换成数字信号,如果想达到比较高的能效比,一般来说只能实现小于等于4比特的计算精度;从工艺上来看,CIMD 与先进工艺相匹配,不会受到PVT 波动的影响,但CIMA 与先进工艺无法匹配,它需要非常复杂的校正模块,因为模拟电路会容易受干扰;在可靠性方面,数字电路抗干扰能力是比较强的,而模拟电路容易受到温度、噪声等因素的影响,所以可靠性会差一些。
从PPA 的角度来看,CIMD 的算力密度和能效比是比较高的,我们的数据在不同先进工艺下,它的能效比可以达到几十TOPS 甚至上百TOPS。因为是纯数字电路,所以CIMD 是没有计算误差的。模拟电路的算力密度也可以做得比较高,能效比甚至会比数字电路更高,但是它是有计算误差的,而且其计算精度会比较低。如果在同等精度下的话,模拟的存算电路并不会比数字的存算电路有太大的优势。但在比较低精度的情况下,模拟电路的能效比会更高一些,但是它的计算误差、精度的问题,还有校正、噪声、温度等这些影响是比较难解决的。所以后摩智能的第一代落地量产的产品是以CIMD 为基础的。
讲完最底层的CIMD,接下来看看怎样把CIMD 组成一个可以用来计算的单元。我们把若干个CIMD Macro 组成一个Macro Group,数据是以数据流stream 的方式流入Macro,结果同样以流的方式流出。这里的一个好处是,在数据流入Macro 过程中,如果feature 数据有很多0,是可以节省一部分功耗的,甚至节省计算时间。这里天然的可以支持feature 稀疏化的效果,不像有些AI处理器里讲稀疏化,比如Orin 的稀疏化是对weight 做稀疏,需要做重新的设计、训练,而我们的计算单元针对feature 可以做稀疏化的加速。
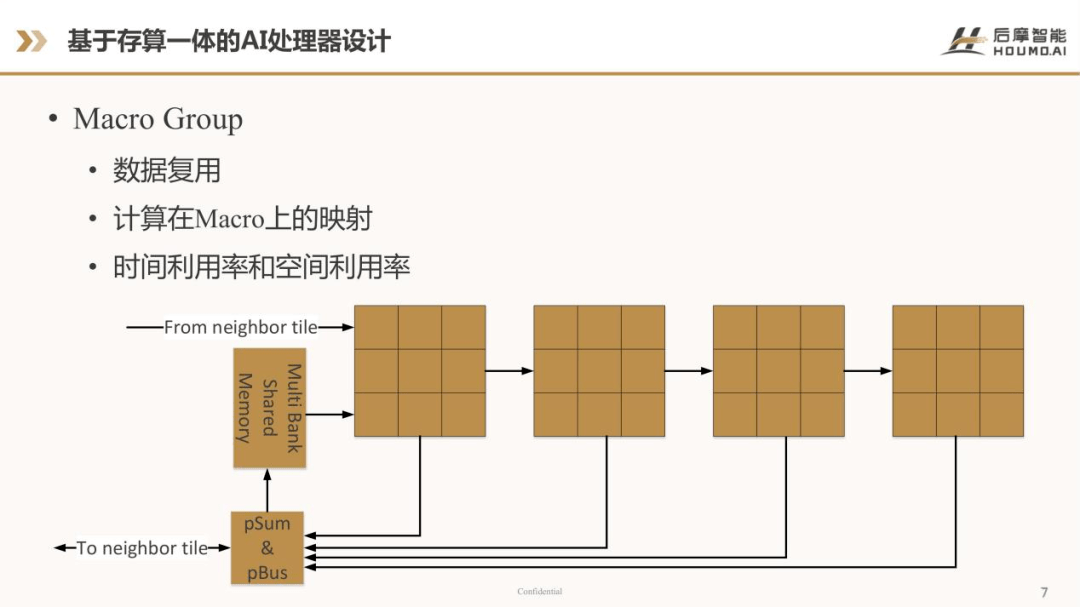
但需要考虑的问题是计算需要在Macro 上映射。上图中举了一个例子,我们的计算单元Macro 会组成一个3×3的阵列,如果是有4个3×3的阵列,可以把它类似组成一个Systolic Array,类似TPU 脉动阵列的形式,数据feature 可以从旁边的Tile 里边或者是Tile SRAM 里的Multi Bank Shared Memory 流入到Macro Group 里,结果同样可以流出Macro Group。
Macro Group 之间的结果可能是一个Partial sum,Partial sum 做一个加法之后,可以写到当前Tile的Shared Memory 里面去,也有可能通过Partial sum bus 流到临近Tile 的计算单元里面。
除了传统的AI NPU 或者AI Core,还要考虑一个利用率的问题,利用率上除了时间利用率,还要考虑空间利用率。比如,上面的例子为什么是一个3×3的结构,因为大多数卷积神经网络中的卷积核,最常用的是3×3 kernel,所以用一个3×3的阵列是可以最高效的计算3×3的卷积。但是除了3×3以外,还有5×5,7×7或者1×1等的卷积规格,这时怎样把一个5×5、7×7的一个kernel映射到3×3的阵列里,这是一个非常难的问题,需要大家仔细考虑怎么把空间上的利用率用满,这也是在用Macro 设计时需要重点关注或考虑的问题。
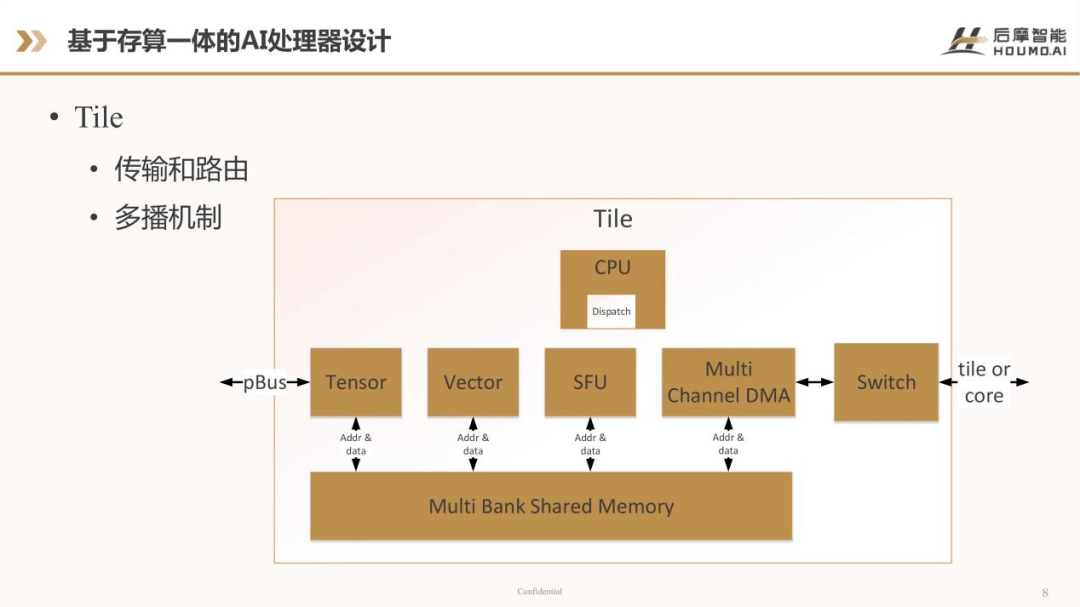
Macro Group 可以作为Tensor Engine 里一个最重要的单元,那Tensor Engine 和其他的一些控制单元或者计算单元,组成一个Tile。从上图可以看出,Tile 里包括了CPU,CPU 主要用来做控制,通过一个指令分发单元把不同的指令分发给Tensor Engine、Vector Engine,Special Function Unit,还有一个多通道的DMA,以及一个Switch。Switch 起到了一个路由的作用,用来在不同的Tile 之间传输数据。我们自己设计了一个数据的传输总线,通过传输和路由,还有多播的机制,让数据可以在不同的Tile,甚至在不同的AI Core 之间进行共享和传播,这样可以极大的提高带宽的利用率,减少数据和memory 之间的传输。
另外,还需要考虑的是Tile 之间的同步问题。比如两个Tile 之间需要共同完成一个计算时,那Tile0 和Tile1 之间怎么进行同步,这也需要在设计中考虑。
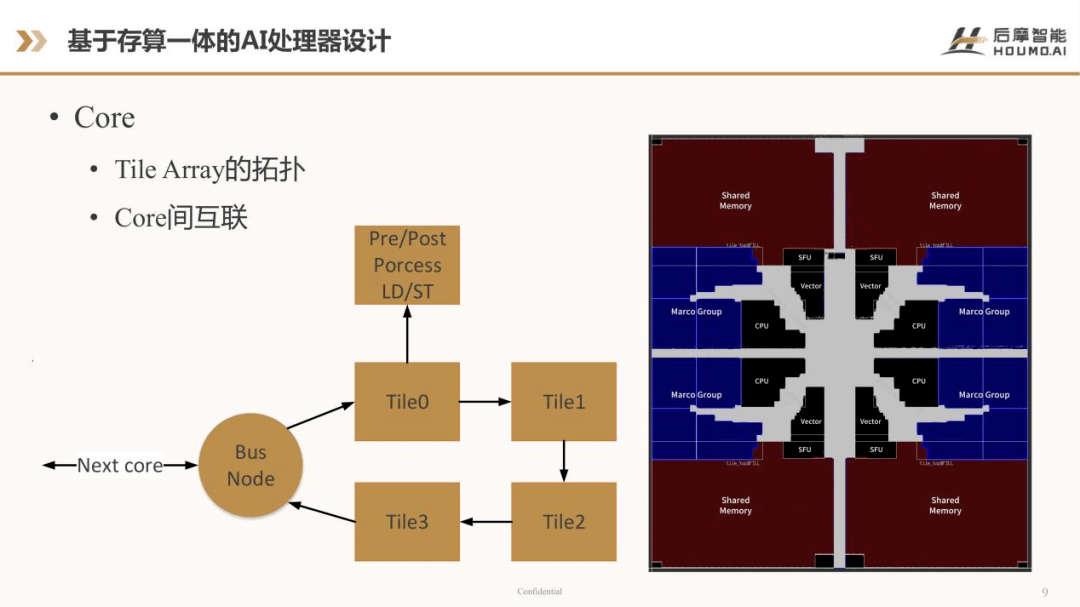
再上一层就是Core level。Core 是由若干个Tile 组成,上图中有4个Tile 的示例了,那Tile 之间以什么样的形式去做拓扑,这也是在做Core level 设计时需要第一个考虑的问题。上图是一个环形的拓扑,4个Tile 组成了1个环。如果是Tile 很多时,也可以是2D Mesh 这样的一个 拓扑形式。
上图的Core level 除了4个Tile 以外,包括一些AI计算里的前处理、后处理的处理单元,Load/Store 等处理单元。Core 里边会有另外的Bus Node 处理单元,Bus Node 用来将不同的Core 之间连接在一起,让不同的Core 之间可以直接传输数据。类似于英伟达最新H100 的架构,H100 架构里面也有类似的设计,它叫DSMEM,是Tensor 之间直接传输数据,而不用通过global memory,也是一个节省数据带宽,节省DDR 带宽很有效的方式。
右边的图是第一个Core 的版图,可以看到这里边包括了Macro Group、shared memory、CPU,还有Special Function Unit 等等,灰色部分就是Core level 里面的前后处理、Load/Stop等处理单元,还有重要的数据传输和互联,这是第一代Core 设计的版图,里面包括了4个Tile。
除了架构的设计以外,基于存算一体的AI 处理器设计,还有很多工程化的问题需要考虑,因为它跟传统的数字电路已经有比较大的差别,这些问题都是我们在实际工程当中遇到的问题。

第一个需要考虑的问题是SI 和PI。SI 是信号完整性,PI 是电源完整性,因为每个Macro 提供的算力很大,有4TOPS。如果有几百TOPS 算力,这几百TOPS 算力在同一时间运转,那对电源和信号完整性是非常大的挑战。
除此之外,Macro DFT 该怎么做?如果不做DFT,实际上是无法实现大规模量产的,我们对Macro 做了非常多DFT 相关的设计,主要包括MBIST 和Repair,Repair 是修复因为面积大了以后可能会有default,我们就需要把它修复。我们做的修复电路里可以测试和修复SRAM bit cell 电路,因为存算本身是由SRAM bit cell 加上一些逻辑电路组成的。同时,还有诊断功能,与传统的SRAM 相比,需要开发自己的lvlib,因为它已经跟传统的SRAM 行为已经有不一样的地方,没有标准的工具可以支持。
另外在CIM 计算模式下,我们设计了定制化的Macro BIST。定制化BIST 需要自己设计BIST RTL,同时可以测试Macro 内部的计算表,所以我们是把Macro 分为SRAM mode 和CIM 两种模式下进行BIST 和Repair 设计。
三、软件工具链
上面主要讲到硬件设计方面的的考虑,如果把硬件设计类比成人的身体,那有了身体还需要有灵魂,而软件工具链就是我们的灵魂。很多人会问基于存算电路的软件工具链、软件生态是否会与传统电路的AI处理器有不一样或者有不兼容的地方?
从软件的角度来看,几乎已经看不到底层的存算电路的存在,它已经在AI处理器里边,通过AI处理器的架构设计把它屏蔽掉。而从软件工具链的角度来看,并不需要过多的考虑底层的存算电路,所以软件工具链需要考虑的事情与用传统的数字电路去做NPU 没有本质上的区别。
我们的软件工具链主要提供了两个开发工具:一个是算子的开发工具,一个是模型的开发工具。对于大多数用户而言,如果没有特殊的自定义算子开发需求,可以用模型开发工具,这里包括了一个加速的算子库,算子库有很丰富的算子,可以cover 80%-90%的算子需求,除了极个别的自定义算子不包括在算子库里边。模型开发SDK 里面还包括了推理引擎、Graph IR、设备内存的分配,设备内存有片内memory 和片外memory 的分配器,还有一个图优化器,以及运行时的一些东西。
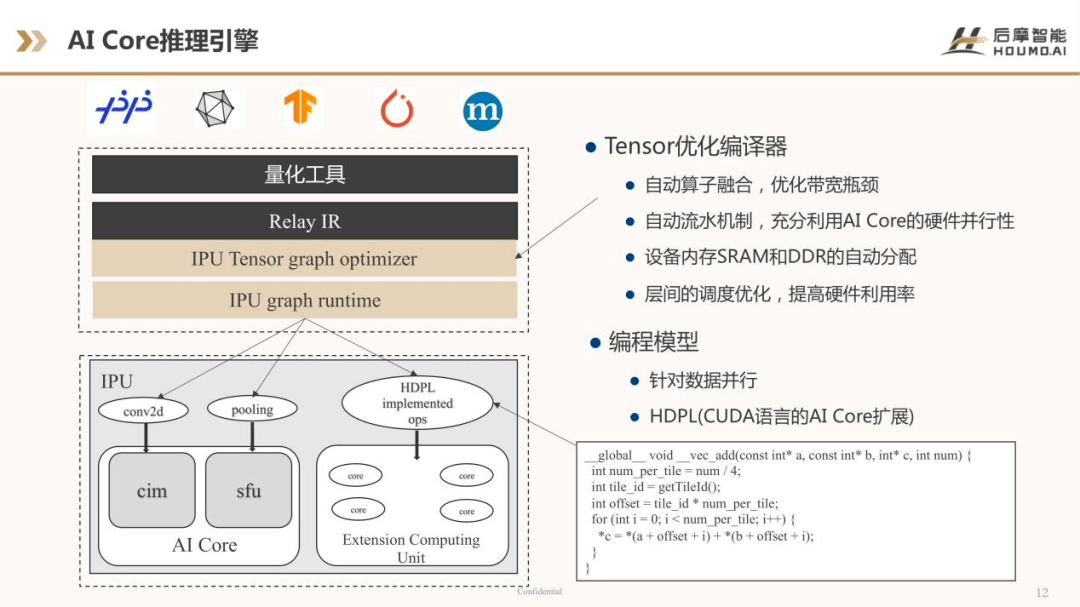
如果是高级的用户,可以开发自己的自定义算子,我们也提供算子的开发工具SDK,这里边包括了编程模型方面,基于CUDA 的扩展语言,叫后摩 Data parallel language 或者叫hardware data parallel language(HDPL语言),还有 Schedule Language,最底层是标准的C++。
编译器方面包括了HDPL 编译器,底层C/C++编译器。工具链方面也提供了丰富的工具链,包括了debugger、调试器、汇编和反汇编的工具、Objdump 工具,还有一个HM profeiler,用它来可以方便的调试CIM。
除此之外,我们也对推理引擎方面有支持。我们的编译器可以让用户从开发类似GPU 的一些程序里,无缝的过渡到AI处理器的开发过程中来,因为我们是一个类CUDA 的编程模型。上层对接的推理引擎可以是多种多样的,包括百度的PaddlePaddle、ONNX、TensorFlow、MXNet 等。这些工具产生的模型,经过量化工具会翻译成一个Relay IR 的中间表达。这个中间表达之后会通过Tensor graph 优化器来做优化,Tensor 优化器做了哪些事情呢?包括自动算子的融合,优化带宽的瓶颈,自动流水的分配机制,可以充分利用AI Core 的硬件并行性,以及设备内存SRAM 和DDR 的自动分配,层间的调度优化等,来提高硬件利用率。
再下一层是IPU graph runtime,即图的运行时。运行时最下层会调用IPU 各种各样的资源。IPU 资源包括了AI Core,就是AI写处理器,还有一些扩展的计算资源,大多数的计算可以通过卷积在CIM 里来实现。还有一些其他的特殊操作,比如最常用的pooling 等类似的操作,可以在Special Function Unit 来实现。如果有自定义的算子还可以通过HDPL 语言的接口,在不同的计算扩展单元里实现。我们的编程模型也是针对数据并行的模型,上图有一个简单的例子,它与CUDA 编程方式是非常接近的。
以上就是本次分享的主要内容,感谢大家的观看。